ETL pipelines – the starting guide
19 December 2022 | Noor Khan





According to Finance Yahoo, the global data pipeline tools market is projected to grow from USD 6.9 billion in 2022 to USD 17.6 by 2027. This significant growth will be driven by a number of factors which contribute to the necessity of data visibility and business intelligence. Data provides invaluable insights to businesses and give the leadership the authority and power to make data-driven well-informed decisions. Data pipelines are the transportation of data from the source to the destination which consists of multiple processing from cleansing, and de-duplication to enrichment.
There are multiple types of data pipelines, however, for the purpose of this guide, we will look at ETL (Extract, Transform, Load) pipelines which are the most common and used widely for data engineering purposes.
What is an ETL Pipeline
An ETL pipeline follows the three-step process pipeline which consists of extracting the data from one or multiple sources, transforming it based on various criteria and loading it into the destination which can range from a data warehouse, data lake or a database.
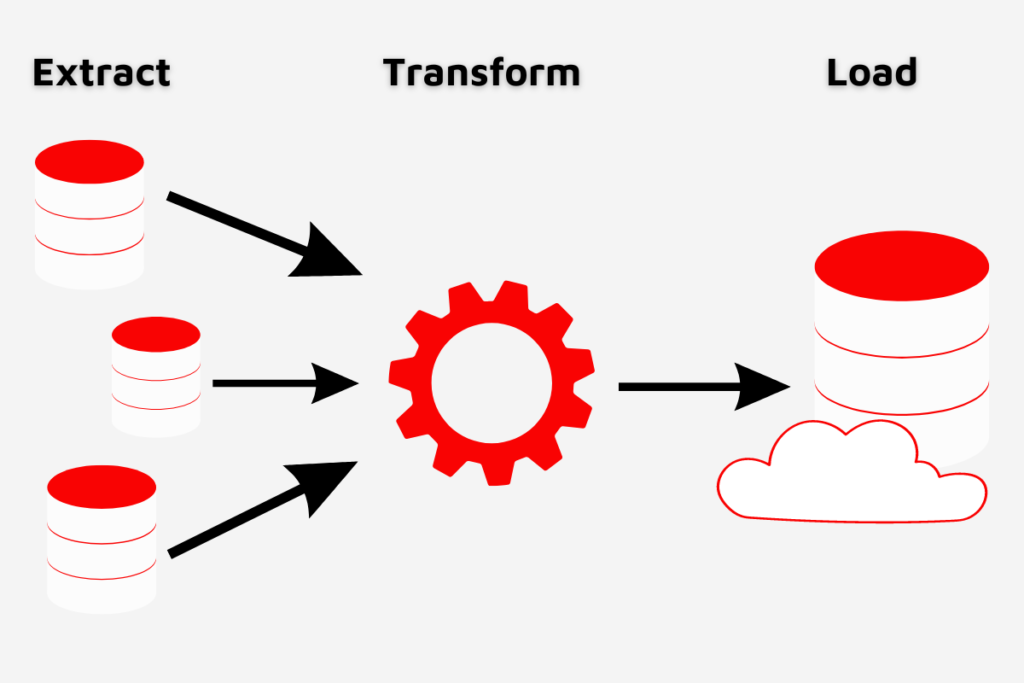
Extract
The extraction step of the ETL pipelines will collect the data from varied sources, this can include CRM data, database data (SQL or NoSQL), marketing data, financial data and any other data that may be required.
Transform
The transforming step of the data includes the process of cleansing the data to remove any duplication, incomplete data or low-quality data. Followed by the enrichment process of mapping the data together to provide an overall picture.
Load
The final step of an ETL pipeline is the loading of the data to the target destination which can range from cloud data warehouses such as Amazon Redshift to data lakes such as Azure Data Lake.
What are the defining characteristics of an ETL pipeline
The process of the ETL pipeline is the defining characteristic which separates it from other alternatives such as ELT (Extract, Transform and Load). There are some other key characteristics of an ETL pipeline and they are as follows:
- Transforming data – General pipelines may not transform the data, whereas transforming the data before loading is a key characteristic of ETL pipelines.
- Batch, stream or real-time data processing – ETL pipeline can be used for various types of data processing to meet the end requirements including batch, stream and real-time.
- Automation – ETL pipeline once built, should automate the process of data processing to remove manual coding and processes.
ETL Pipeline technologies
There are a wide variety of technologies on the market from world-leading vendors that enable data engineers to architect and develop robust, scalable pipelines. Here are some of the key technologies that can be used for data ETL data pipeline development:
Snowflake – Snowflake can be used to remove the process of manually ETL manual coding and data cleansing with self-service pipelines.
Apache Kafka – Can be used for stream and real-time data processing within ETL data pipelines.
Apache Spark – This can be a great option to employ for data processing of real-time data providing high speed of data accessibility on large volumes of data.
AWS Elastic MapReduce – This can be used to speed up the data processing time for a better data turnaround time.
AWS Data Pipeline – AWS data pipeline service enables the creation of ETL data pipelines to automate the process of moving and transforming the data.
Azure Data Factory – This enables you to construct ETL data pipelines with the ability to create them without or without code.
Each vendor will differ and will not be suitable for every type of business and data. Therefore, choosing the right one for your data is key. If you do not have the expertise in-house to make the right decision, then consider getting in touch with an expert.
ETL Pipeline use cases
ETL pipelines are crucial for the success of organisations that want to maximise the potential of their data. ETL pipelines are used to ensure a smooth flow of data from source to destination to provide analytics for data science and BI teams. There are many use cases for data pipelines and they include:
Collecting and collating market research data with ETL AWS pipelines
Employing leading AWS technologies, our highly skilled data engineers built a robust, scalable data pipeline infrastructure to ingest large volumes of market research data. The data through the ETL pipeline is cleansed, processed, validated and enriched to provide invaluable insights for commercial purposes.
Read the full story on how high data accessibility and accuracy were ensured with ETL pipelines.
Ardent ETL pipeline development
We have worked on many data types to build secure, scalable and robust data pipelines with leading technologies for a wide variety of clients. Ensuring your data pipelines are built with growth, scalability and security in mind is essential to long-term success. Data pipelines are vital to driving Business Intelligence and value from your data which is spread across many disparate sources. If you are looking to build data pipelines from scratch to a new or existing source or want to create a data pipeline from a new source to your existing data storage facility, we can help. Our expert data engineers are proficient in world lead technologies including the likes of Snowflake, AWS, Azure, Spark, Kafka and more.
Get in touch to find out more or explore our data pipeline development services to get started.
Ardent Insights

Overcoming Data Administration Challenges, and Strategies for Effective Data Management
Businesses face significant challenges to continuously manage and optimise their databases, extract valuable information from them, and then to share and report the insights gained from ongoing analysis of the data. As data continues to grow exponentially, they must address key issues to unlock the full potential of their data asset across the whole business. [...]

Are you considering AI adoption? We summarise our learnings, do’s and don’ts from our engagements with leading clients.
How Ardent can help you prepare your data for AI success Data is at the core of any business striving to adopt AI. It has become the lifeblood of enterprises, powering insights and innovations that drive better decision making and competitive advantages. As the amount of data generated proliferates across many sectors, the allure of [...]

Why the Market Research sector is taking note of Databricks Data Lakehouse.
Overcoming Market Research Challenges For Market Research agencies, Organisations and Brands exploring insights across markets and customers, the traditional research model of bidding for a blend of large-scale qualitative and quantitative data collection processes is losing appeal to a more value-driven, granular, real-time targeted approach to understanding consumer behaviour, more regular insights engagement and more [...]

Services
About
UK
US
India

