Building data pipelines – a starting guide
7 October 2022 | Noor Khan





Data visibility can be a huge driving factor for organisation growth. Poor data visibility can lead to a lack of compliance with data security, difficulty in understanding business performance and increased complexity in dealing with system performance issues. Developing secure, robust and scalable data pipelines can empower businesses to gain data visibility by connecting the dots to gain the full picture and improve their understanding of the entire business.
What are data pipelines
A data pipeline is a series of processing steps that the data will go through from the source which can be a software, system or a tool to a destination which can be a data warehouse, data lake or other another data storage structure. Data pipelines will collect and collate data from disparate sources and process it for efficient storage and analysis. Data pipeline development, when done right can offer multiple benefits to organisations from ensuring data is clean to enabling end users to gain useful, meaningful insights.
Why you need a pipeline for your data
If you have data that is sat across a wide variety of sources and systems that are not connected, then you are not accessing the full potential of your data that could provide you with meaningful insights. These insights can inform better decision-making and support any monetisation efforts if you are looking to sell data and insights to clients. For example, we worked with one of our market research clients to build a pipeline that would collect data from their data storage and feed it through to the end clients' data analytics and reporting tool.
Key pipeline challenges
There are many challenges organisations can face with data pipelines. Data pipelines that are poorly architected or are not built with scalability in mind can be challenging to deal with. Here are some key challenges you might find with data pipelines:
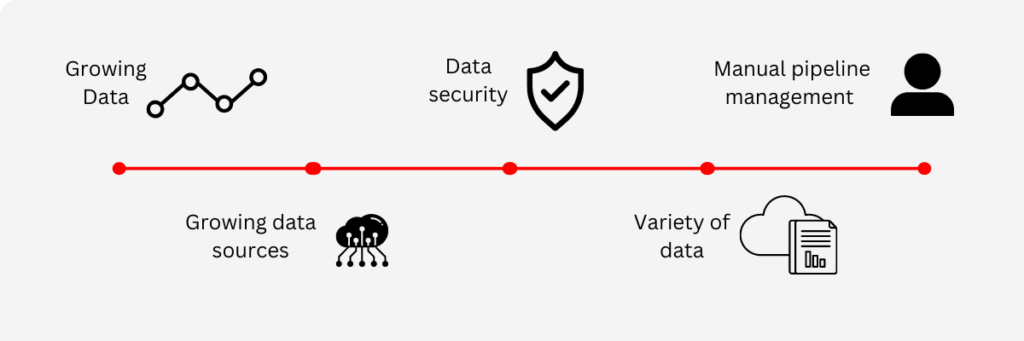
- Growing data – Growing data can cause challenges with your data pipelines if they were not developed to handle large volumes of data.
- Growing data sources – Collating data from multiple sources can be challenging, however, the more data sources added to the pipeline the more complex they become.
- Data security – Data security should be a priority for any organisation, especially those that deal with sensitive or consumer data. Collating and collecting data from a disparate number of sources can increase the risk. However, ensuring you are following best practices can mitigate any risks.
- Managing pipelines manually – Manual effort on any process can drain productivity and require a lot more time and resources. Building pipelines with automation in mind can save you time and resources in the long term.
- Variety of data without standardization – Data that is varied in size, format and structure can be difficult to organize and standardize. Therefore, this data will need to be mapped in a common format to ensure that you can obtain the insights you require.
Read the full article on key challenges with managing data pipelines.
Key benefits from pipelines
Having efficient, effective pipelines with automation can provide a wealth of benefits to organisations. These are some of the key benefits of data pipelines:
- Centralized data to improve data visibility
- Uncover compelling insights to drive data-driven decision making
- Improve data security with data visibility
- Create an efficient data structure to mitigate issues and resolve them quickly if any arise
- Forecast and make predictions based on your data
- Get the full picture with unified data
Data pipeline development technologies
There are several world-leading technologies you can employ to build your data pipelines. At Ardent, our engineers work with multiple technologies including the likes of AWS Redshift, AWS S3, AWS DynamoDB, Apache Hadoop, Apache Spark, Python and much more. Choosing the right technologies and platforms to build your data pipelines with will depend on a number of factors including:
- Data – The volume, variety and velocity of data you are dealing with as well as the number of data sources.
- Budget – Most popular tools and platforms will have costs associated with them whether that’s licensing costs or finding individuals with the right skill set and training in those technologies.
- Scalability – Is scalability a key requirement for you? It should be for most instances, in which case you will need to choose technologies that will allow you to scale your data pipelines.
- Latency – How quickly do you need to be able to access your data and have it ready for analysis and reporting? If you are looking at real-time latency then you will need to select technologies that will allow that.
Find out about our technology partners.
Types of data pipelines
There are four most popular types of data pipelines which include batch data pipelines, ETL data pipelines, ELT data pipelines, and real-time data pipelines. We will explore each of these below.
ETL data pipelines
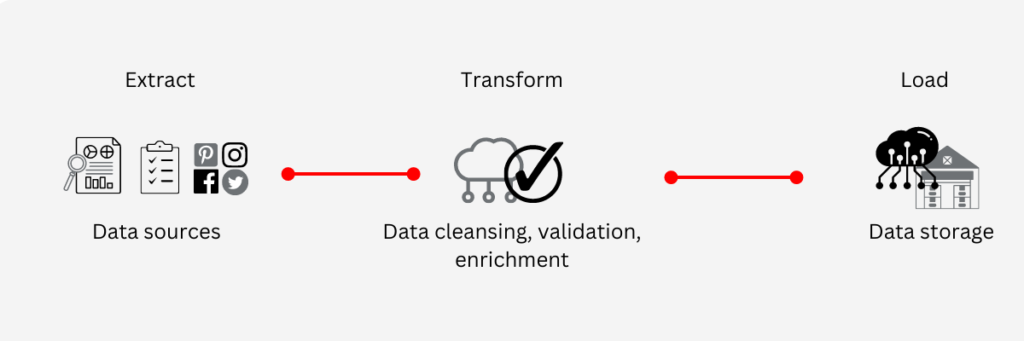
ETL is the most common type of data pipeline that has been the main structure of data pipelines for decades. The structure of the ETL data pipeline is extract, transform and load. The data is extracted from disparate sources, it is transformed through the processes of cleansing, validation and enrichment to match it to a pre-defined format and loaded into the data storage infrastructure whether that is a data warehouse, database, data mart or a data lake.
Read the success story on ETL pipeline development with AWS infrastructure.
ELT data pipelines
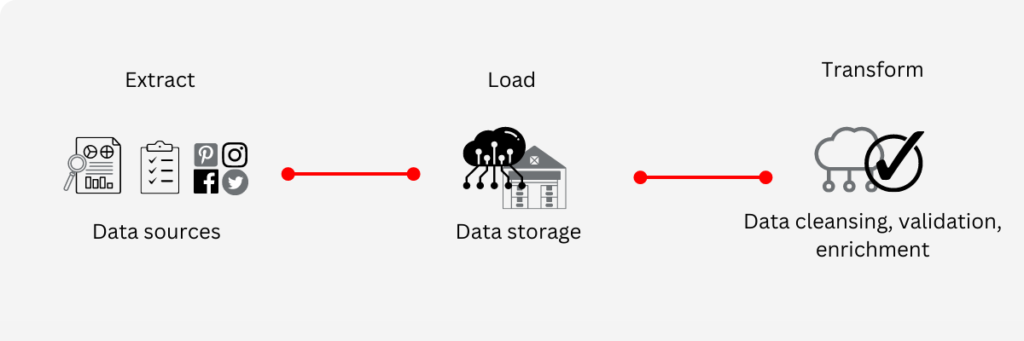
The ELT structure is a more recent type of data pipeline which follows the structure of extract, load and transform. This is a more flexible approach when it comes to dealing with data that will vary over time as it is extracted, loaded and then transformed. The data is extracted from multiple sources (same as the ETL structure), it is then loaded directly into a data storage infrastructure (data warehouse, database, data lake or a data mart) and then it is formatted in line with the end requirements. ELT is more suitable for organisations that may use the data for multiple different purposes. As it is a relatively new structure, it can be difficult to find experts in this type of data pipeline development.
Batch pipelines
Batch pipelines focus on processing data in set blocks (batches) hence the name. This makes the processing of large volumes of data quicker and more efficient. This type of processing is typically carried out during down times such as evenings, nights and weekends when the systems are not all fully in use. Batch pipelines are for those organisations that may want to collect all historic data to make data-driven decisions, a great example of this is market research companies collecting survey data. Batch processing can take a few minutes, hours or even days depending on the quantity of data.
Read our client success story on batch pipeline development.
Real-time data pipelines
Real-time data pipelines are those that process the data in real time and make it available and accessible for data reporting and analysis instantly. This can be a complex and challenging process, especially when dealing with large volumes of data coming in at varying speeds. Real-time data pipelines are suitable for organisations that want to process data from streaming locations such as financial markets. There is an increasing demand for real-time analytics therefore, it can be expected that real-time data pipelines will become more prominent in the upcoming years.
Read our client success story involving real-time data processing.
Data pipeline automation
Automation of any process offers invaluable benefits from improved productivity and removal of human error to streamlined and efficient processes. This is no different to automating data pipelines. There are several key benefits of automating data pipelines and they include:
- Save time and resources – You can save significant time and resources and consequently costs as you automate your data pipeline processes.
- Streamlined data pipelines – With automation, you streamline the entire process and remove the need for manual coding.
- Improve turnaround – Improve data accessibility and turnaround time for speedier data analysis and reporting.
Outsourcing data pipeline development
Building data pipelines in-house can be a good idea if you have the in-house resource, experience, skills and expertise. However, if you do not, then it might be worth considering outsourcing data pipeline development. Here is why you might consider the outsourcing approach:
- Work with experienced engineers – When you outsource your data pipeline development you will be working with experienced engineers that have gained invaluable knowledge which can ensure your data pipelines are built to meet your requirements.
- Access highly skilled and trained professionals – You can access professionals that have specific training and skills in building pipelines without having to go through lengthy and costly recruitment processes.
- Avoid licencing costs for technologies and platforms – When you are working with a third party, they will cover the costs of technology licensing as they are more than likely to have existing licensing in place. This again saves you costs in comparison to carrying out the project in-house.
- Costs effective – If you decide to opt for the in-house route without the right skills you may face complex challenges which may lead to costly errors. Therefore, investing in the right data engineering company will save you long-term costs.
Data pipeline success story
For a leading market research client, our data engineers architected robust, scalable data pipelines with AWS infrastructure to ingest data from multiple sources, cleaned it and enriched it. The speed processing of data was a challenge as it was considerably large volumes of data. However, our data engineering employed EMP (Elastic MapReduce) to significantly reduce the processing time.
Read the full story here: Powerful insights driving growth for global brands
Ardent data pipelines development services
Ardent’s highly experienced data engineers have worked on a number of projects building robust, scalable data pipelines with built-in automation to ensure a smooth flow of data with minimal manual input. Our teams work with you closely to understand your business challenges, your desired outcomes and your end goal and objectives to build data pipelines that will fulfil your unique needs and requirements. Whether you are dealing with data that is spread across disparate sources or have constant large volumes of data coming in, we can help, get in touch to find out more or to get started.
Explore our data engineering services or our data pipeline development services.
Ardent Insights

Overcoming Data Administration Challenges and Strategies for Effective Data Management
Businesses face significant challenges to continuously manage and optimise their databases, extract valuable information from them, and then to share and report the insights gained from ongoing analysis of the data. As data continues to grow exponentially, they must address key issues to unlock the full potential of their data asset across the whole business. [...]
Read More... from Building data pipelines – a starting guide

Are you considering AI adoption? We summarise our learnings, do’s and don’ts from our engagements with leading clients.
How Ardent can help you prepare your data for AI success Data is at the core of any business striving to adopt AI. It has become the lifeblood of enterprises, powering insights and innovations that drive better decision making and competitive advantages. As the amount of data generated proliferates across many sectors, the allure of [...]
Read More... from Building data pipelines – a starting guide

Why the Market Research sector is taking note of Databricks Data Lakehouse.
Overcoming Market Research Challenges For Market Research agencies, Organisations and Brands exploring insights across markets and customers, the traditional research model of bidding for a blend of large-scale qualitative and quantitative data collection processes is losing appeal to a more value-driven, granular, real-time targeted approach to understanding consumer behaviour, more regular insights engagement and more [...]
Read More... from Building data pipelines – a starting guide

Services
About
UK
US
India

